

El corpus paralelo inglés/español, PaEnS, forma parte de un proyecto más amplio, PaCorES, (www.pacores.eu), Parallel Corpora Spanish, cuyo objetivo es reunir una serie de corpus paralelos bilingües con el español como lengua central. Hasta el momento, el proyecto incluye otros tres corpus en distintos grados de consecución, todos ellos libremente disponibles en línea: Corpus PaGes Alemán < > Español, Corpus PaChes Chinese < > Español y Corpus PaFres French < > Español.
PaEnS es un corpus paralelo bilingüe compuesto por dos partes principales: el corpus nuclear y los suplementos.
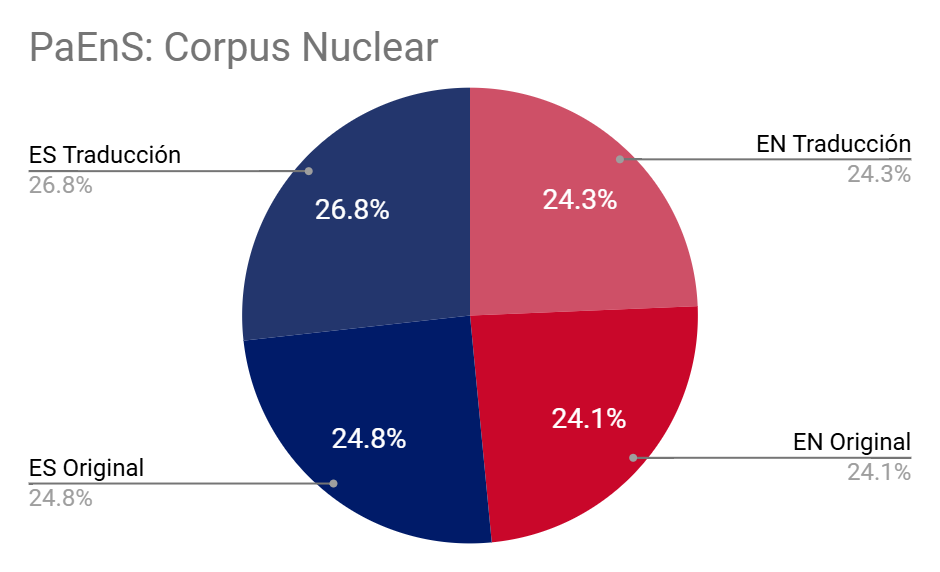
El corpus nuclear está está compuesto por 120 textos originales en inglés y 140 originales en español y sus respectivas traducciones. Incluye obras de ficción -novelas y relatos cortos, que suponen alrededor del 80%- así como de no ficción (20,24%) -especialmente psicología, ensayos y textos de divulgación científica-. Las obras seleccionadas no están representadas por los textos completos, sino por muestras, lo que permite una mejor transversalidad de los textos. Los cortes en el texto (original y traducción) están marcados.
Esta parte de PaEnS (vid. abajo) contiene más de 50 millones de tokens y 1.5 millonesá de bisegmentos, es decir, pares de unidades alineadas (oraciones o unidades suboracionales).
Para garantizar la calidad se han verificado manualmente los textos incluidos a diferentes niveles y el alineado automático, realizado inicialmente por LF-Aligner ocasionalmente en combinación con otras herramientas como youalign o Gargantua, ha sido revisado manualmente. Desde 2024 utilizamos principalmente Bertalign para el alineamiento, que con su tecnología basada en transformers alcanza una mayor precisión y consistencia.
En lo que respecta al etiquetado gramatical (POS tagging), hemos seleccionado las herramientas que actualmente ofrecen los resultados más precisos según el estado del arte: Stanza para el inglés y Freeling para el español. Tras la lematización y el etiquetado se llevó a cabo una revisión semimanual para identificar y corregir errores sistemáticos, y posteriormente las etiquetas resultantes se asignaron al conjunto de etiquetas Universal POS, que recoge las principales categorías gramaticales. En futuras versiones se prevé incluir categorías más detalladas.
De cada ocurrencia se facilita la fuente original que incluye información sobre el autor, título, año de la primera publicación, en su caso, de la edición utilizada y la parte o capítulo dentro de la obra a la que pertenece la ocurrencia. Las indicaciones bibliográficas completas de las obras incluidas en PaEnS figuran aqui.
Los suplementos comprenden un total de más de 110 millones de palabras. Si no se especifica lo contrario, no se ha realizado revisión manual alguna. Los suplementos por el momento incluyen:
En un futuro próximo se prevé incorporar nuevas colecciones de textos bilingües de origen diverso.
Esperamos que PaEnS, sea un recurso multifuncional capaz de satisfacer necesidades bien diferenciadas. Nuestro objetivo es construir un recurso lingüístico representativo para el inglés y el español que pueda ser explotado para múltiples propósitos. Aquí se incluye la investigación general en lingüística contrastiva, tipología lingüística, estudios de traducción y lexicografía bilingüe o el suministro de datos de entrenamiento a sistemas de traducción automática. PaEnS, es además un recurso muy útil para traductores y estudiantes de inglés o español como lengua extranjera de niveles intermedios y avanzados para obtener una multitud de sugerencias de traducción, realizadas por humanos y mostradas en ejemplos de uso.
A pesar de todos los esfuerzos, estamos seguros de que se han deslizado errores. Por ello, le agradecemos que si los detecta nos lo comunique haciendo clik aquí.
Nota:
Si usas PaEnS
en tus trabajos, por favor cita el artículo de abajo y comunícanoslo a: corpuspaens@usc.es. Así contribuyes a la sostenibilidad del proyecto.
Doval, Irene (2023): The English–Spanish parallel corpus PaEnS. Current trends on digital technologies and gaming for language teaching and linguistics, eds. I. Santos Díaz et al. Berlin: Peter Lang. pp.145-164.
Estadísticas PaEnS (Noviembre 2023)
PaEnS: Corpus nuclear
| LENGUA | TOKENS | PALABRAS | MSTTRATIO* | BISEGMENTOS | OBRAS |
| Inglés Original | 13.123.320 | 11.364.819 | 0,535 | 806.226 | 120 |
| Español Traducción | 13.746.700 | 12.046.344 | 0,529 | ||
| Español Original | 12.864.001 | 11.292.490 | 0,541 | 703.343 | 140 |
| Inglés Traducción | 13.176.524 | 11.541.833 | 0,527 | ||
| Total | 52.910.545 | 46.245.486 | 0,531 | 1.509.569 | 260 |
Suplementos 1: Europarl v7
| LENGUA | TOKENS | PALABRAS | MSTTRATIO* | BISEGMENTOS |
| Inglés | 39.481.818 | 35.918.308 | 0,485 | 1.536.548 |
| Español | 41.476.923 | 37.600.223 | 0,465 | |
| Total | 80.958.741 | 73.518.531 | 0,475 | 1.536.548 |
Suplementos 2: TED-Talks
| LENGUA | TOKENS | PALABRAS | MSTTRATIO* | BISEGMENTOS |
| Inglés | 8.676.842 | 7.043.470 | 0,476 | 431.095 |
| Español | 8.338.726 | 6.816.425 | 0,506 | |
| Total | 17.015.568 | 13.859.895 | 0,491 | 431.095 |
Suplementos 3: Global Voices
| LENGUA | TOKENS | PALABRAS | MSTTRATIO* | BISEGMENTOS |
| Inglés | 15.285.853 | 12.724.972 | 0,558 | 680.530 |
| Español | 16.361.642 | 13.826.084 | 0,528 | |
| Total | 31.647.495 | 26.551.056 | 0.543 | 680.530 |
Suplementos 4: OpenSubtitles v2018
| LENGUA | TOKENS | PALABRAS | MSTTRATIO* | BISEGMENTOS |
| Inglés | 69.377.387 | 54.446.668 | 0,516 | 7.745.559 |
| Español | 62.207.848 | 49.007.151 | 0,570 | |
| Total | 131.585.235 | 103.453.819 | 0.543 | 7.745.559 |
*MSTTR es la TTR (relación Tipo/Token, por sus siglas en inglés) promedio para cada segmento no superpuesto de igual tamaño (en este caso, 1000 tokens).
(Modificado: 19/11/2024, Release v2.0)




