

O corpus paralelo inglés/español, PaEnS, forma parte dun proxecto máis grande, PaCorES,(www.pacores.eu), Parallel Corpora Spanish, cuxo obxetivo é reunir unha serie de corpus paralelos bilingües co español como lingua central. Ata o momento, o proxecto inclúe outros tres corpus en distintos grados de consecución, todos eles libremente disponibles en líña: Corpus PaGes Alemán < > Español, Corpus PaChes Chinese < > Español e Corpus PaFres French < > Español.
PaEnS é un corpus paralelo bilingüe composto por dúas partes principais: o corpus nuclear e os suplementos.
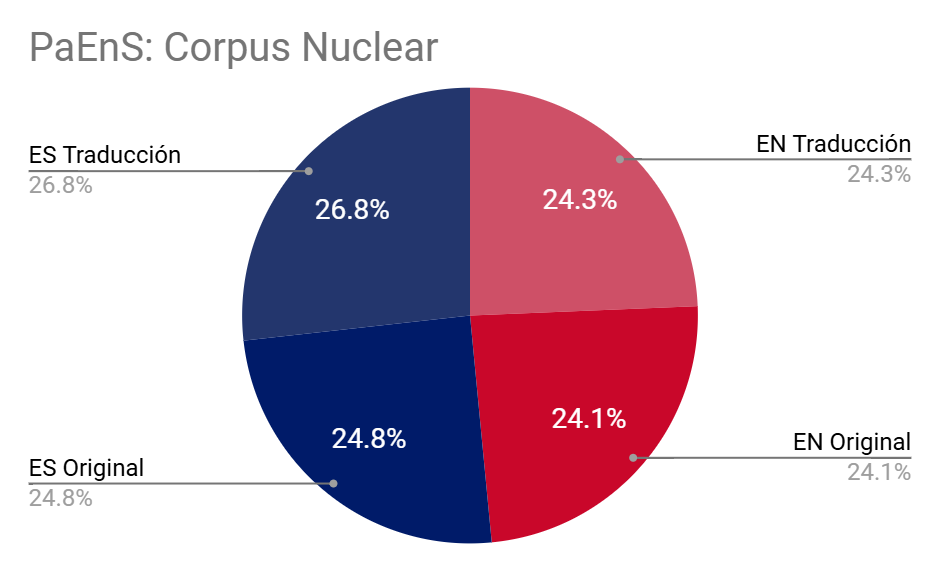
óO corpus nuclear está composto por 120 textos orixinais en inglés e 140 orixinais en español e as súas respectivas traducións. Inclúe obras de ficción: novelas e contos, que representan preto do 80% - así como de non ficción (20,24%) -especialmente de psicoloxía, ensaio e textos de divulgación científica-. As obras seleccionadas non son representada polos textos completos, senón por mostras, o que permite unha mellor transversalidade dos textos. Márcanse as pausas no texto (orixinal e tradución).
Esta parte de PaEnS (vid. abajo) contén máis de 50 millóns de tokens e 1.5 millóns de bisegmentos, é dicir, pares de unidades aliñadas (oracións ou unidades de suboracións).
Para garantir a calidade, verificouse manualmente os textos incluídos a distintos niveis e o aliñamento automático, realizado inicialmente por LF-Aligner, ocasionalmente en combinación con outras ferramentas como youalign ou Gargantua, foi revisado manualmente. Dende 2024 empregamos principalmente Bertalign para o aliñamento, que coa súa tecnoloxía baseada en transformers alcanza unha maior precisión e consistencia.
No que respecta ao etiquetado gramatical (POS tagging), seleccionamos as ferramentas que actualmente ofrecen os resultados máis precisos según o estado da arte: Stanza para o inglés e Freeling para o español. Tras a lematización e o etiquetado levouse a cabo unha revisión semimanual para identificar e correxir errores sistemáticos, e posteriormente as etiquetas resultantes asignáronse ao conxunto de etiquetas Universal POS, que recolle as principais categorías gramaticais. En futuras versións prevése incluir categorías máis detalladas.
Para cada ocorrencia achégase a fonte orixinal, que inclúe información sobre o autor, título, ano de primeira publicación, se é o caso, da edición utilizada e a parte ou capítulo da mesma ao que pertence a ocorrencia. As indicacións bibliográficas completas das obras incluídas en PaEnS figuran aqui.
Os suplementos comprenden un total de máis de 110 millóns de palabras. Se non se especifica o contrario, non se realizou ningunha revisión manual. Os suplementos neste momento inclúen:
Nun futuro próximo está previsto incorporar novas coleccións de textos bilingües de diversa procedencia.
Agardamos que PaEnS , ser un recurso multifuncional capaz de satisfacer necesidades ben diferenciadas. O noso obxectivo é construír un recurso lingüístico representativo para o inglés e o español que poida ser explotado para múltiples propósitos. Isto inclúe investigacións xerais en lingüística contrastiva, tipoloxía lingüística, estudos de tradución e lexicografía bilingüe ou a subministración de datos de formación en sistemas de tradución automática. PaEnS tamén é un recurso moi útil para tradutores e estudantes de inglés ou español como lingua estranxeira de niveis intermedio e avanzado para obter multitude de suxestións de tradución realizadas por humanos e mostradas en exemplos de uso.
A pesar de tódolos esforzos, estamos seguros de que apareceron erros. Por este motivo, agradecemos que se os detectas, por favor, nos avises facendo clic aquí.
Nota:
Se usa PaEnS
no seu traballo, por favor cita o artigo de abaixo e notifíqueno a: corpuspaens@usc.es,
así contribúes á sostibilidade do proxecto.
Doval, Irene (2023): The English–Spanish parallel corpus PaEnS. Current trends on digital technologies and gaming for language teaching and linguistics, eds. I. Santos Díaz et al. Berlin: Peter Lang. pp.145-164.
Estatísticas PaEnS (Novembro 2023)
PaEnS: Corpus nuclear
| LINGUA | TOKENS | PALABRAS | MSTTRATIO* | BISEGMENTOS | OBRAS |
| Inglés Orixinal | 13.123.320 | 11.364.819 | 0,535 | 806.226 | 120 |
| Español Tradución | 13.746.700 | 12.046.344 | 0,529 | ||
| Español Orixinal | 12.864.001 | 11.292.490 | 0,541 | 703.343 | 140 |
| Inglés Tradución | 13.176.524 | 11.541.833 | 0,527 | ||
| Total | 52.910.545 | 46.245.486 | 0,531 | 1.509.569 | 260 |
Suplementos 1: Europarl v7
| LINGUA | TOKENS | PALABRAS | MSTTRATIO* | BISEGMENTOS |
| Inglés | 39.481.818 | 35.918.308 | 0,485 | 1.536.548 |
| Español | 41.476.923 | 37.600.223 | 0,465 | |
| Total | 80.958.741 | 73.518.531 | 0,475 | 1.536.548 |
Suplementos 2: TED-Talks
| LINGUA | TOKENS | PALABRAS | MSTTRATIO* | BISEGMENTOS |
| Inglés | 8.676.842 | 7.043.470 | 0,476 | 431.095 |
| Español | 8.338.726 | 6.816.425 | 0,506 | |
| Total | 17.015.568 | 13.859.895 | 0,491 | 431.095 |
Suplementos 3: Global Voices
| LINGUA | TOKENS | PALABRAS | MSTTRATIO* | BISEGMENTOS |
| Inglés | 15.285.853 | 12.724.972 | 0,558 | 680.530 |
| Español | 16.361.642 | 13.826.084 | 0,528 | |
| Total | 31.647.495 | 26.551.056 | 0.543 | 680.530 |
Suplementos 4: OpenSubtitles v2018
| LINGUA | TOKENS | PALABRAS | MSTTRATIO* | BISEGMENTOS |
| Inglés | 69.377.387 | 54.446.668 | 0,516 | 7.745.559 |
| Español | 62.207.848 | 49.007.151 | 0,570 | |
| Total | 131.585.235 | 103.453.819 | 0.543 | 7.745.559 |
*MSTTR é a TTR (relación Tipo/Token, polas súas siglas en inglés) media para cada segmento non
superposto de tamaño igual (neste caso, 1000 tokens).
(Modificado: 19/11/2024, Release v2.0)




